2024. 6. 24. 16:53ㆍ데이터분석 기술블로그
6월 13일부터 19일까지 스프린트로 진행됐던, 총 5일간의 데이터 분석 프로젝트가 끝나고 주요 결과를 정리하였다.
- 스프린트 주제 : 연예인 스캔들이 소속사 주가에 미치는 영향
- 해당 프로젝트를 통해 알아보고 싶은 것 : 영향을 주는 스캔들의 종류를 찾아보고 실제로 스캔들로 인한 주가 변동이 발생하는 지 확인
- 데이터 분석 프로세스 : 문제 정의 - 가설 수립 - 데이터 수집과 정리 - 패턴 분석 - 가설 검증 - 결론 및 의사 결정
데이터 수집
스캔들 기사 수집
스캔들 기사를 수집하여 구글 스프레드 시트에 취합하였다. 데이터를 테이블 형식으로 만들고 어떤 분류로 컬럼을 구성할 것인지 정했다. 스캔들 기사는 2019년부터 24년까지 5년내 발생한 사건들로 자료를 수집했다. 각자 검증하려는 가설들이 달라서 사건의 종류나 기사 검색량 등을 함께 조사했고 스크랩한 기사는 최소 5개 이상을 수집했다.

파이썬 라이브러리
파이썬 라이브러리에서 주가 데이터를 가져왔다. 가져온 소스는 FinanceDataReader와 한국 증권 거래소 소스이다. FinanceDataReader는 KODEX 200 ETF (069500)와 KODEX 코스닥150 ETF(229200)의 수정 종가를 불러올 수 있다.
가설 검증 및 결과
가설 : 스캔들 기사 발행일 기준으로 주가가 하락한다면 주가 회복일까지 5일 이상 걸릴 것이다.
1) 데이터수집
수집한 자료에서 해당 가설을 검증하기 위해 기사 발행일의 주가 변동률과 회복일을 추가로 수집했다.
- d : 기사 발행일 기준 종가 변동률
- r1 : 기사 발행일 종가 기준 주가 회복일
- r2 : 기사 발행일 시가 기준 주가 회복일
2) 데이터 정제
정상 범위에서 크게 벗어난 이상치를 발견했다. 해당 데이터가 분석 결과에 왜곡을 줄 수 있다고 판단하여 해당 값에 대한 결측치 처리를 하였다. 결측치 처리 후, r1과 r2의 평균치를 출력했다.
3)일표본 t검정
해당 검정법은 표본의 평균이 기준값과 비슷한 수준인지 비교할 때 사용하는 검정법이다. r1의 평균값은 대략 5(일)이다. 평균값을 기준값으로 설정하여 다음과 같은 귀무가설과 대립가설을 설정하였다.
귀무가설 : 스캔들 기사 발행일을 기준으로 주가가 하락한다면, 주가 회복일은 5일이다.
대립가설 : 스캔들 기사 발행일을 기준으로 주가가 하락한다면, 주가 회복일은 5일보다 크거나 적다.
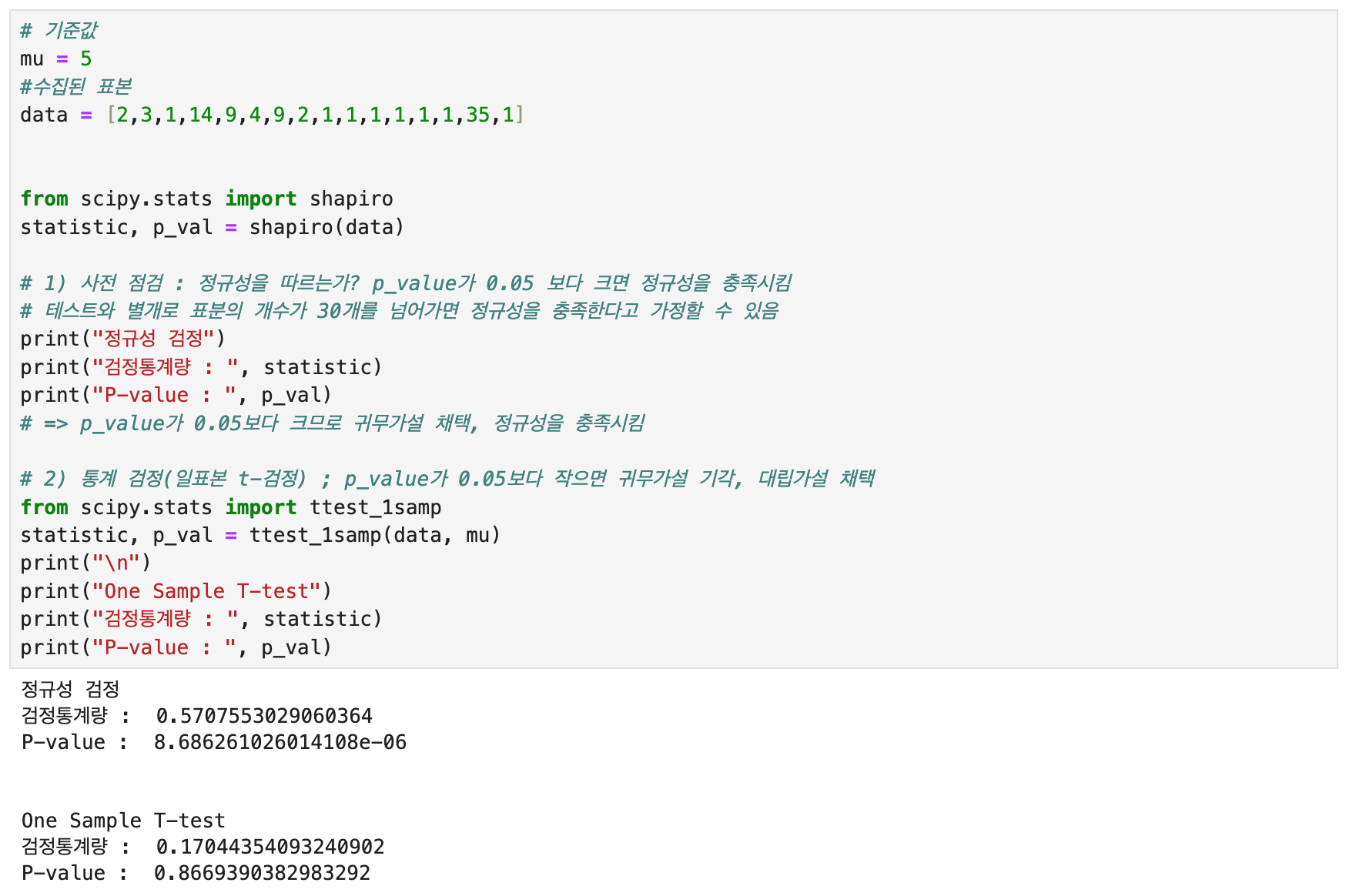
결과 : 정규성 검정에서 p-value가 0에 가깝도록 매우 작은 값이 나왔다. 표본의 개수가 너무 적었고, 결과적으로 정규성을 충족하지 못하였다. 해당 검정법으로는 정확한 결과를 기대하기 어려웠다.
3)일표본 윌콕슨 부호-순위 검정
정규성을 충족하지 않아도 실행할 수 있는 검정법을 찾다가 윌콕슨 부호-순위 검정법을 알게되었다. 해당 검정은 일표본 t검정의 비모수적 대안으로, 표본 중앙값이 특정 값과 다른지 여부를 검정하는 방법이다. GPT에게 해당 검정법의 샘플을 만들어달라고 했고, 나는 두 개의 샘플을 비교하는 검정법이 아니었기 때문에 단일 표본으로 실행할 수 있는 검정법으로 진행했다.
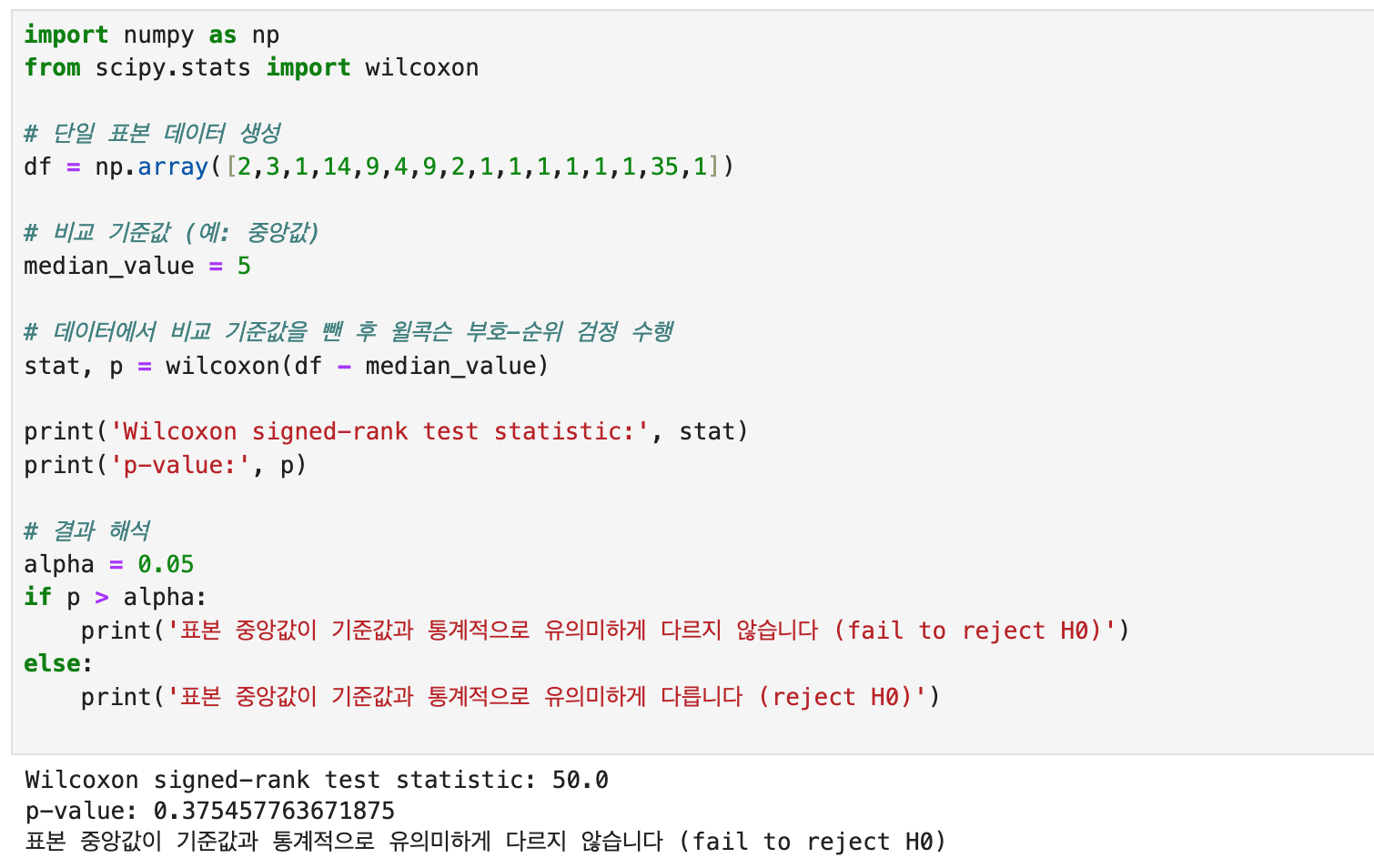
검정 결과 :
귀무가설과 대립가설은 일표본t검정과 같고, 표본 데이터 입력 후 출력된 결과는 p-value > alpha 이다. 출력된 p값이 0.05보다 크므로 귀무가설을 기각할 충분한 증거가 없었다. 따라서 기준값인 5(일)과 통계적으로 유의미하게 다르지 않다. 라는 결론을 지을 수 있었다.
최종 결론 : 스캔들 기사로 인해 기업 주가가 하락했다면, 최소 5거래일 이후에 회복될 확률이 높다.
회고
이번 스프린트 주제는 재밌었던 것과는 별개로 어려운 점이 많았다. 우선 제공되는 데이터셋이 없어 팀원 모두가 직접 데이터를 수집해야 했고 어떤 데이터를 수집할 지를 논의하여 정해야 했다. 또한 최근 5년 내 기사를 스크랩하면 분석하는데 있어 충분한 갯수가 나올 줄 알았는데 생각보다 부족해서 분석에 필요한 표본 집단이 적었다는 것이다.
원래 시도해보려고 했던 파이썬의 감정 분석 라이브러리도 시간적 여유가 없어 못한 것 등등 여러모로 아쉬움이 남지만 직접 데이터를 수집하는 경험과 배웠던 검정법 외에 새로운 검정법을 사용해 본 것은 분명 귀중한 경험이었다. 데이터를 수집하고 처리하는 일이 이렇게 시간이 많이 걸리고 어려운 것이라는 걸 알았으니까.
주식이란게 워낙 변수가 많아서 해당 주제로 데이터분석 스프린트를 하는게 적절했는지는 모르겠지만 평소 관심을 가졌던 주제로 재밌게 했고 초반부터 어려운 일을 했으니 그만큼 배운점도 있고 단기간에 성장이 많이 된 느낌이었다
'데이터분석 기술블로그' 카테고리의 다른 글
| 상세 페이지(스크롤 이벤트 추적) (0) | 2024.07.01 |
|---|---|
| 성동2기 전Z전능 데이터 분석가 32일차 [GA4 초기 환경 구성] (0) | 2024.06.28 |
| 성동2기 전Z전능 데이터 분석가 22일차[데이터분석 스프린트 시작] (0) | 2024.06.13 |
| 성동2기 전Z전능 데이터 분석가 21일차[데이터분석 기법 : AB테스트] (1) | 2024.06.12 |
| 성동2기 전Z전능 데이터 분석가 20일차[데이터 시각화] (0) | 2024.06.11 |